Virtual Library of 1 Million New Macrolide Scaffolds Could Help Speed Drug Discovery
For Immediate Release
Researchers from North Carolina State University have created the largest publicly available virtual library of macrolide scaffolds. The library – called V1M – contains chemical structures and computed properties for 1 million macrolide scaffolds with potential for use as antibiotics or cancer drugs.
“As chemists, we’re only able to look at a tiny portion of the actual chemical universe,” says Denis Fourches, assistant professor of chemistry at NC State and corresponding author of a paper describing the work. “If we were trying to synthesize and test all possible individual chemicals of interest, it would take way too much time and be too expensive. So we have to use computers to explore those unknown parts of the chemical space.”
One way that chemists utilize computers is by using them to enumerate, or virtually generate, new molecules and compare their predicted properties to those of existing drugs. This in silico screening process quickly and inexpensively identifies compounds with desirable properties that experimental chemists can then synthesize and test.
Macrolides are a family of chemicals mainly used as antibiotics and anti-cancer drugs. Their unique ring structure enables them to bind to difficult protein targets. Some of them are considered drugs of last resort, especially for drug-resistant bacteria.
“Macrolides are natural products,” Fourches says. “These chemicals are produced by bacteria as a means to kill other bacteria. But it takes 20 to 25 chemical steps to synthesize these very complex compounds, which is a time-consuming and expensive process. So if you want to find new compounds, computer simulation is by far the fastest way to do it.”
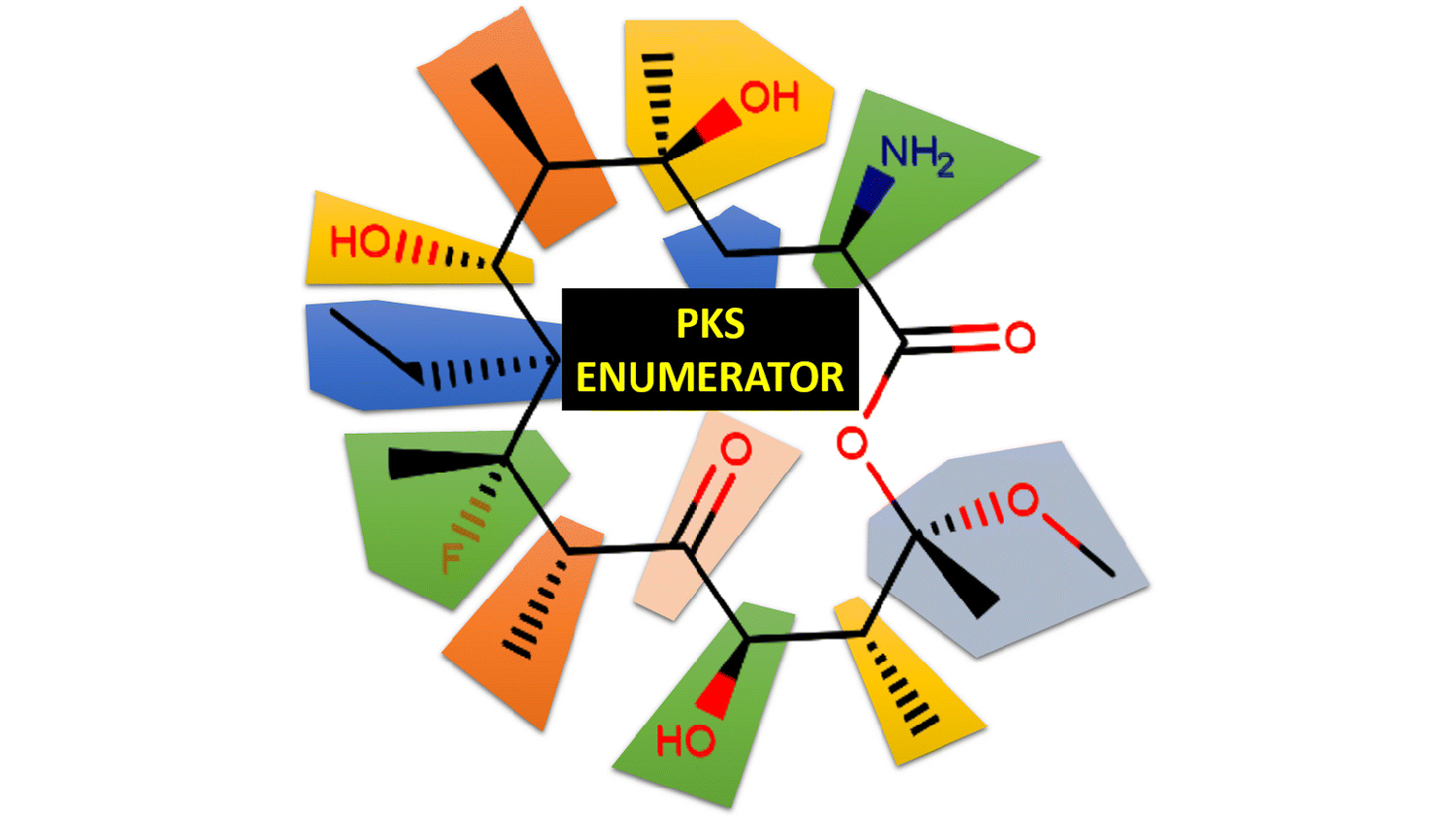
Fourches and his colleagues created a computer software program called the PKS Enumerator, which generates very large libraries of virtual chemical analogues of macrolide drugs. The software uses chemical building blocks extracted from a set of 18 known bioactive macrolides, breaking each one down into its component chemical parts, and then reshuffling them to create new compounds according to a series of rules and user-constraints. The resulting library of new macrolides – V1M – classifies the new compounds by size, weight, topology and hydrogen bond donors and acceptors.
“We wanted to create a virtual library of completely new chemicals that no one has probably ever synthesized, but those compounds still needed to be similar enough to known macrolide drugs in order to make this library relevant for the research community,” Fourches says. “V1M is the first public domain library of these new macrolides, which are all chemically similar to the 18 known bioactive macrolides we analyzed. Hopefully other researchers can use the library to further screen and identify some compounds that may be useful in drug discovery.”
The research appears in the Journal of Cheminformatics. NC State graduate student Phyo Phyo Kyaw Zin is first author. Gavin Williams, associate professor of chemistry at NC State, also contributed to the work.
-peake-
Note to editors: An abstract of the paper follows.
“Cheminformatics-based enumeration and analysis of large libraries of macrolide scaffolds”
DOI: 10.1186/s13321-018-0307-6
Authors: Phyo Phyo Kyaw Zin, Gavin Williams, Denis Fourches, North Carolina State University
Published: Journal of Cheminformatics
Abstract:
We report on the development of a cheminformatics enumeration technology and the analysis of a resulting large dataset of virtual macrolide scaffolds. Although macrolides have been shown to have valuable biological properties, there is no ready-to-screen virtual library of diverse macrolides in the public domain. Conducting molecular modeling (especially virtual screening) of these complex molecules is highly relevant as the organic synthesis of these compounds, when feasible, typically requires many synthetic steps, and thus dramatically slows the discovery of new bioactive macrolides. Herein, we introduce a cheminformatics approach and associated software that allows for designing and generating libraries of virtual macrocycle/macrolide scaffolds with user-defined constitutional and structural constraints (e.g., types and numbers of structural motifs to be included in the macrocycle, ring size, maximum number of compounds generated). To study the chemical diversity of such generated molecules, we enumerated V1M (Virtual 1 million Macrolide scaffolds) library, each containing twelve common structural motifs. For each macrolide, we calculated several key properties, such as molecular weight, hydrogen bond donors/acceptors, topological polar surface area. In this study, we discuss (1) the initial concept and current features of our PKS (polyketides) Enumerator software, (2) the chemical diversity and distribution of structural motifs in V1M library, and (3) the unique opportunities for future virtual screening of such enumerated ensembles of macrolides. Importantly, V1M is provided in the Supplementary Material of this paper allowing other researchers to conduct any type of molecular modeling and virtual screening studies. Therefore, this technology for enumerating extremely large libraries of macrolide scaffolds could hold a unique potential in the field of computational chemistry and drug discovery for rational designing of new antibiotics and anti-cancer agents.
- Categories:


