A Decade of Genes, Chemicals and Human Health: The Comparative Toxicogenomics Database Turns 10

Editor’s Note: This is a guest post by Allan Peter Davis, project manager of the Comparative Toxicogenomics Database in NC State’s Department of Biological Sciences. The post regards an October 17 paper published in Nucleic Acids Research lead-authored by Davis.
What do you get a scientific database for its ten-year anniversary? Aluminum is the traditional gift, but do I want to run the risk of getting Alzheimer’s disease? That’s the kind of stuff I think about while at work, making links between what might seem like disconnected data.
I’m the biocuration project manager of the Comparative Toxicogenomics Database (CTD), and this month we’re celebrating our ten-year anniversary. CTD is a public toxicogenomic database that describes how environmental chemicals interact with genes to affect human health. And according to CTD, the metal aluminum interacts with over 1,900 genes and can be linked to several diseases, including Alzheimer’s. So, maybe not aluminum; instead, maybe just some cupcakes?
Ten years ago (November 12, 2004, to be exact), CTD was launched on the web. I’ll confess I wasn’t there for it (I was wrapping up a career in the private sector, working on another disease database). I don’t know how much fanfare there was on that day. CTD has always been, and still is, managed by a small team: a couple of software engineers, some biologists, and a system administrator. How much fanfare could there have been?
But a lot of changes have happened to CTD since 2004, deserving of a real celebration, including, not least, a new home. CTD originated at the Mount Desert Island Biological Laboratory, located on a small island off the coast of northern Maine, but moved south in 2012 when the principal investigator, Dr. Carolyn Mattingly was appointed associate professor in NC State’s Department of Biological Sciences.
CTD has changed in other ways too, evolving into a premier toxicology resource for information about chemicals and their biological effects, especially on diseases. At its launch in 2004, CTD was unique as it was the only public resource that collected and harmonized data on genes important to chemical responses in diverse organisms. That’s what made CTD comparative and why it has a ‘C’ as its first letter. Comparing genetic and molecular mechanisms from different vertebrates and invertebrates helps identify conserved regions and responses, which may in turn help scientists understand more about how our environment affects our health. Lessons learned from experimental model organisms can inform human health protection.
I joined CTD in 2005 to design and map out the biocuration project. Biocuration is a unique subsection of bioinformatics. According to the International Society for Biocuration it is defined as “the translation and integration of information relevant to biology into a database or resource that enables integration of the scientific literature as well as large data sets.” Try explaining that one to Aunt Mildred at Thanksgiving.
Basically, I get paid to read scientific papers. All day long. And so does my team. I lead a group of Ph.D.-level scientists that read and manually code the primary toxicology literature, transforming authors’ free-text information into a structured format using controlled vocabularies. Why? Because once that information is coded using the same tools, we can start making connections between results from different research groups publishing articles in different journals across decades. And then we can start linking all that knowledge together and transform it into discoveries. That’s the fun part.
Last year, we published a study looking at 88,000 scientific articles from over 4,700 journals during the last seven decades. Because all of these papers were coded using the same controlled vocabularies by CTD biocurators, we were able to link information from data reported in 1948 to data reported today, producing a wealth of information for interconnected chemicals, genes, and diseases.
To date, CTD has manually curated over 1.2 million scientific statements for 11,000 different chemicals, 35,000 genes, and 6,300 diseases. By integrating that knowledge, the database computationally generates another 17 million predictions linking chemicals, genes, and diseases. It is this combination of data integration and novel predictions that makes CTD resourceful for generating testable hypotheses about the molecular mechanisms of environmental diseases.
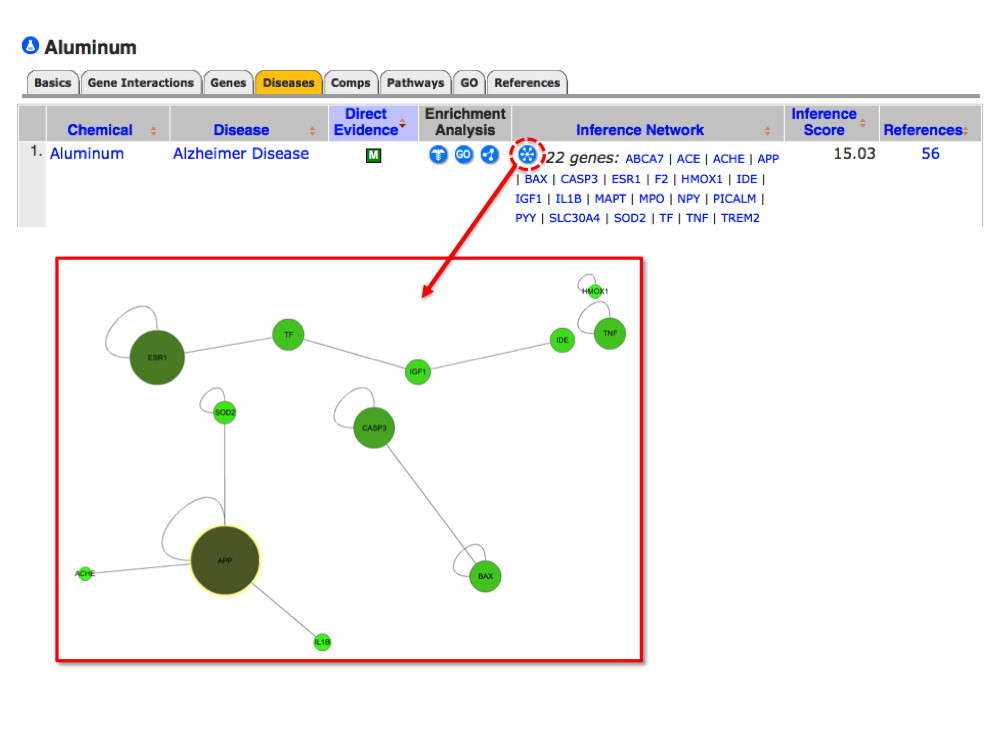
So, could exposure to aluminum actually be a risk factor for developing Alzheimer’s? It’s definitely a controversial issue in the field, and far from settled, but by integrating data from various publications, CTD produces an inference network of 22 genes that connect aluminum to Alzheimer’s disease. These molecular predictions, and the numerous analytical and visualization tools built into CTD, provide scientists with a possible roadmap to test in the laboratory. For example, 11 of those 22 genes are involved in cell death (and seven of them are specifically involved in neuron death, the kind of stuff you might anticipate in Alzheimer’s disease). With a few mouse-clicks, CTD will even draw you a map showing how some of those 22 genes are known to physically interact and regulate each other, producing an interaction module. Using this information, researchers can design experiments to test these predictions connecting the metal to biological events.
And scientists do use CTD for their research. I think that’s the strongest testament to our success. Nearly 600 scientific articles have cited or used CTD in their own publications, and our content is picked up and further disseminated into the scientific community by over 50 other databases. Such peer recognition and value inspires us to continue to expand the content and scope of the database.
Now how do I send those celebratory, virtual cupcakes to my co-workers?
This post is based on a recent publication: Davis, AP, Grondin, CJ, Lennon-Hopkins, K., Saraceni-Richards, C., Sciaky, D., King, B.L., Wiegers, T.C., and Mattingly, C.J. 2014. The Comparative Toxicogenomics Database’s 10th year anniversary: update 2015. Nucleic Acids Research. doi: 10.1093/nar/gku935.
- Categories: